About data profiling
To profile data in a data source (for example, a database or a file) means to examine and collect information about that data. The purpose of the examination can be, for example, to determine whether this data is accurate and complete or whether the data can be used for business analysis. The information collected during the data profiling refers to data type, structure, content, relationships, and so on.
After uploading data sources, the data is automatically profiled. To get the best results from automatic data profiling, you can prepare your data (for example, set up the date formats or exclude footer rows). For details, see Preparing data files.
The automatic profiling system identifies the following:
Data can be classified as follows:
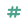 | Measure |
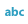 | Dimension |
 | Geo dimension |
 | Date |
 | Time |
 | DateTime |
Data Preparation identifies data roles for the columns based on the following criteria:
Date type columns become
Date, DateTime, or Time.String columns become:
- Geo dimensions — If a column name includes one of the geo keywords (for example, Country).
- Dimensions — If a column name includes one of the dimension keywords (for example, “ID” in Product ID).
Numeric columns become:
- Geo dimensions — If a column name includes one of the geo keywords (for example, latitude).
- Dimensions — If a column name includes one of the dimension keywords (for example, Transaction ID) or when a column is a Primary Key (PK) or Foreign Key (FK). For example, Product key.
- Measures — If a column name does not have any keywords mentioned earlier and is not a PK/FK.
Geo dimension keywords: "address", "country", "city", "province", "latitude", "longitude", "coordinates", "lat", "long", "state", "zipcode", "zip", "region", "location", "locations", "countries", "cities", "regions", "states", "addresses", "provinces".
Dimension keywords: "id", "ids", "key", "keys", "identifier", "identifiers", "code", "dim", "age", "codes".
Note: If a column name includes both types of keywords, the suffix takes priority. For example, Location ID becomes a dimension because the suffix is ”ID”.
For general information on data roles, see About dimensions and measures.
For the columns containing measures, the system suggests an aggregation type based on the column name. If a column name is not recognized, then the default aggregation is set to Sum. The following aggregation types are available when creating a dataset:
- None (is the only option for OLAP data sources; not available for other data sources)
- Sum
- Average
- Count
- Minimum
- Maximum
The aggregation type that is defined at the time of a dataset creation is a default type for that measure in a visualization. More aggregation types are available when clicking a measure in the widget settings pane. For details, see About aggregation for measures.
The joins between tables are suggested based on their common columns (with similar content and similar names) or when columns are Primary Keys (PK) and Foreign Keys (FK).
There are four join types:
 Inner join
Inner join  Left join
Left join Right join
Right join Full outer join
Full outer join
For details, see About data joins.
For files, automatic data profiling may require manual adjustments. For details, see Change the data role and Define joins between data sources.
Comments
0 comments